Grid5000:Home
 Grid'5000 is a precursor infrastructure of SLICES-RI, Scientific Large Scale Infrastructure for Computing/Communication Experimental Studies.
|
|
Grid'5000 is a large-scale and flexible testbed for experiment-driven research in all areas of computer science, with a focus on parallel and distributed computing, including Cloud, HPC, Big Data and AI. Key features:
Older documents:
|
Random pick of publications
Five random publications that benefited from Grid'5000 (at least 2932 overall):
- Hee-Soo Choi, Priyansh Trivedi, Mathieu Constant, Karën Fort, Bruno Guillaume. Au-delà de la performance des modèles : la prédiction de liens peut-elle enrichir des graphes lexico-sémantiques du français ?. Actes de JEP-TALN-RECITAL 2024. 31ème Conférence sur le Traitement Automatique des Langues Naturelles, volume 1 : articles longs et prises de position, Jul 2024, Toulouse, France. pp.36-49. hal-04623008 view on HAL pdf
- Albert d'Aviau de Piolant, Hayfa Tayeb, Bérenger Bramas, Mathieu Faverge, Abdou Guermouche, et al.. Improving energy efficiency of HPC applications using unbalanced GPU power capping. HCW (Ipdps workshop), Jun 2025, Milan (Italie), Italy. hal-04883872v2 view on HAL pdf
- Chaima Zoghlami, Rahim Kacimi, Riadh Dhaou. Leveraging RL for Efficient Collection of Perception Messages in Vehicular Networks. Global Information Infrastructure and Networking Symposium (GIIS 2024), Feb 2024, Dubai, United Arab Emirates. à paraître. hal-04408979 view on HAL pdf
- Cédric Prigent, Melvin Chelli, Alexandru Costan, Loïc Cudennec, René Schubotz, et al.. Efficient Resource-Constrained Federated Learning Clustering with Local Data Compression on the Edge-to-Cloud Continuum. HiPC 2024 - 31st IEEE International Conference on High Performance Computing, Data, and Analytics, Dec 2024, Bengaluru (Bangalore), India. pp.1-11, 10.1109/HiPC62374.2024.00033. hal-04779813 view on HAL pdf
- Houssam Elbouanani, Chadi Barakat, Walid Dabbous, Thierry Turletti. Troubleshooting Distributed Network Emulation. Annals of Telecommunications - annales des télécommunications, 2024, 79 (April), pp.227-239. 10.1007/s12243-024-01010-y. hal-04373896 view on HAL pdf
Latest news
![]() Cluster Spirou is now in default queue at Louvain
Cluster Spirou is now in default queue at Louvain
We are pleased to announce that the Spirou[1] cluster of the newly installed Louvain site is now available in the default queue.
Spirou is a cluster composed of 8 Lenovo ThinkSystem SR630 V2 nodes, each featuring:
Be aware that we noticed I/Os inconsistencies on this cluster.
We advise users to take this into account when performing experimentations on the cluster. See the following bug for more information: https://intranet.grid5000.fr/bugzilla/show_bug.cgi?id=16938
This cluster was funded by the Fonds de la Recherche Scientifique – FNRS (F.R.S.–FNRS), and its operation is supported by F.R.S.–FNRS and the Wallonia region (SPW).
[1] https://www.grid5000.fr/w/Louvain:Hardware#spirou
Best regards,
Grid'5000 Technical Team
-- Grid'5000 Team 10:24, 12 January 2026 (CEST)
![]() End of support for centOS7/8 and centOSStream8 environments
End of support for centOS7/8 and centOSStream8 environments
Support for the centOS7/8 and centOSStream8 kadeploy environments is stopped due to the end of upstream support and compatibility issues with recent hardware.
The last version of the centOS7 environments (version 2024071117), centOS8 environments (version 2024071119), centOSStream8 environments (version 2024070316) will remain available on /grid5000. Older versions can still be accessed in the archive directory (see /grid5000/README.unmaintained-envs for more information).
-- Grid'5000 Team 08:44, 4 December 2025 (CEST)
![]() Ecotaxe cluster is now in default queue at Nantes
Ecotaxe cluster is now in default queue at Nantes
We are pleased to announce that the ecotaxe cluster of Nantes is now available in the default queue.
As a reminder, ecotaxe is a cluster composed of 2 HPE ProLiant DL385 Gen10 Plus v2 servers[1].
Each node features:
To submit a job on this cluster, the following command may be used:
oarsub -t exotic -p ecotaxe
This cluster is co-funded by Région Pays de la Loire, FEDER and REACT EU via the CPER SAMURAI [3].
[1] https://www.grid5000.fr/w/Nantes:Hardware#ecotaxe
[2] The observed throughput depends on multiple parameters such as the workload, the number of streams, ... [3] https://www.imt-atlantique.fr/fr/recherche-innovation/collaborer/projet/samurai
-- Grid'5000 Team 14:10, 02 December 2025 (CET)
![]() Some changes on the hardware configuration of Grenoble nodes
Some changes on the hardware configuration of Grenoble nodes
We recently did some hardware changes on clusters yeti, troll and dahu.
The changes are as follows:
- yeti-[1,3]: 1× NVMe
- yeti-[2,4]: 2× NVMe
oarsub request. For example:oarsub -I -p "dahu and opa_count > 0"
-- Grid'5000 Team 14:50, 24 November 2025 (CEST)
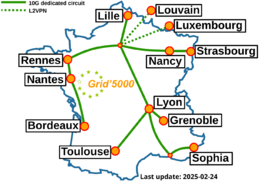
Grid'5000 sites
Current funding
INRIA
|
CNRS
|
UniversitiesIMT Atlantique |
Regional councilsAquitaine |

{kind=link}