Grid5000:Home: Difference between revisions
No edit summary |
No edit summary |
||
| (10 intermediate revisions by 5 users not shown) | |||
| Line 1: | Line 1: | ||
__NOTOC__ __NOEDITSECTION__ | __NOTOC__ __NOEDITSECTION__ | ||
{|width="95%" | |||
|- valign="top" | |||
|bgcolor="#888888" style="border:1px solid #cccccc;padding:2em;padding-top:1em;"| | |||
[[File:Slices-ri-white-color.png|260px|left|link=https://www.slices-ri.eu]] | |||
<b>Grid'5000 is a precursor infrastructure of [https://www.slices-fr.eu SLICES-FR], the French node of [https://www.slices-ri.eu SLICES-RI], Scientific Large Scale Infrastructure for Computing/Communication Experimental Studies.</b> | |||
<br/> | |||
Content on this website is partly outdated. Technical information remains relevant. | |||
|} | |||
{|width="95%" | {|width="95%" | ||
|- valign="top" | |- valign="top" | ||
|bgcolor="#f5fff5" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | |bgcolor="#f5fff5" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | ||
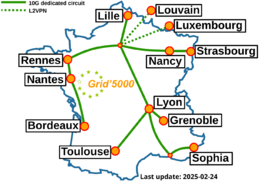
[[Image: | [[Image:g5k-backbone.png|thumbnail|260px|right|Grid'5000|link=https://www.grid5000.fr]] | ||
'''Grid'5000 is a large-scale and flexible testbed for experiment-driven research in all areas of computer science, with a focus on parallel and distributed computing including Cloud, HPC | '''Grid'5000 is a large-scale and flexible testbed for experiment-driven research in all areas of computer science, with a focus on parallel and distributed computing, including Cloud, HPC, Big Data and AI.''' | ||
Key features: | Key features: | ||
* provides '''access to a large amount of resources''': | * provides '''access to a large amount of resources''': 15000 cores, 800 compute-nodes grouped in homogeneous clusters, and featuring various technologies: PMEM, GPU, SSD, NVMe, 10G and 25G Ethernet, Infiniband, Omni-Path | ||
* '''highly reconfigurable and controllable''': researchers can experiment with a fully customized software stack thanks to bare-metal deployment features, and can isolate their experiment at the networking layer | * '''highly reconfigurable and controllable''': researchers can experiment with a fully customized software stack thanks to bare-metal deployment features, and can isolate their experiment at the networking layer | ||
* '''advanced monitoring and measurement features for traces collection of networking and power consumption''', providing a deep understanding of experiments | * '''advanced monitoring and measurement features for traces collection of networking and power consumption''', providing a deep understanding of experiments | ||
| Line 15: | Line 24: | ||
<br> | <br> | ||
Read more about our [[Team|teams]], our [[Publications|publications]], and the [[Grid5000:UsagePolicy|usage policy]] of the testbed. Then [[Grid5000:Get_an_account|get an account]], and learn how to use the testbed with our [[Getting_Started|Getting Started tutorial]] and the rest of our [[:Category:Portal:User|Users portal]]. | Read more about our [[Team|teams]], our [[Publications|publications]], and the [[Grid5000:UsagePolicy|usage policy]] of the testbed. Then [[Grid5000:Get_an_account|get an account]], and learn how to use the testbed with our [[Getting_Started|Getting Started tutorial]] and the rest of our [[:Category:Portal:User|Users portal]]. | ||
<br> | <br> | ||
Published documents and presentations: | |||
* [[Media:Grid5000.pdf|Presentation of Grid'5000]] (April 2019) | * [[Media:Grid5000.pdf|Presentation of Grid'5000]] (April 2019) | ||
* [https://www.grid5000.fr/mediawiki/images/Grid5000_science-advisory-board_report_2018.pdf Report from the Grid'5000 Science Advisory Board (2018)] | * [https://www.grid5000.fr/mediawiki/images/Grid5000_science-advisory-board_report_2018.pdf Report from the Grid'5000 Science Advisory Board (2018)] | ||
| Line 39: | Line 46: | ||
==Latest news== | ==Latest news== | ||
<rss max=4 item-max-length="2000">https://www.grid5000.fr/ | <rss max=4 item-max-length="2000">https://www.grid5000.fr/rss/G5KNews.php</rss> | ||
---- | ---- | ||
[[News|Read more news]] | [[News|Read more news]] | ||
| Line 50: | Line 57: | ||
* [[Lille:Home|Lille]] | * [[Lille:Home|Lille]] | ||
* [[Luxembourg:Home|Luxembourg]] | * [[Luxembourg:Home|Luxembourg]] | ||
* [[Louvain:Home|Louvain]] | |||
|width="33%" bgcolor="#f5f5f5" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | |width="33%" bgcolor="#f5f5f5" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | ||
* [[Lyon:Home|Lyon]] | * [[Lyon:Home|Lyon]] | ||
* [[Nancy:Home|Nancy]] | * [[Nancy:Home|Nancy]] | ||
* [[Nantes:Home|Nantes]] | * [[Nantes:Home|Nantes]] | ||
* [[Rennes:Home|Rennes]] | |||
|width="33%" bgcolor="#f5f5f5" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | |width="33%" bgcolor="#f5f5f5" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | ||
* [[Sophia:Home|Sophia-Antipolis]] | * [[Sophia:Home|Sophia-Antipolis]] | ||
* [[Strasbourg:Home|Strasbourg]] | |||
* [[Toulouse:Home|Toulouse]] | * [[Toulouse:Home|Toulouse]] | ||
|- | |- | ||
| Line 62: | Line 71: | ||
== Current funding == | == Current funding == | ||
{|width="100%" cellspacing="3" | {|width="100%" cellspacing="3" | ||
|- | |- | ||
| width="50%" bgcolor="#f5f5f5" valign="top" align="center" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | | width="50%" bgcolor="#f5f5f5" valign="top" align="center" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | ||
===INRIA=== | ===INRIA=== | ||
[[Image:Logo_INRIA.gif|300px]] | [[Image:Logo_INRIA.gif|300px|link=https://www.inria.fr]] | ||
| width="50%" bgcolor="#f5f5f5" valign="top" align="center" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | | width="50%" bgcolor="#f5f5f5" valign="top" align="center" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | ||
===CNRS=== | ===CNRS=== | ||
[[Image:CNRS-filaire-Quadri.png|125px]] | [[Image:CNRS-filaire-Quadri.png|125px|link=https://www.cnrs.fr]] | ||
|- | |- | ||
| width="50%" bgcolor="#f5f5f5" valign="top" align="center" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | | width="50%" bgcolor="#f5f5f5" valign="top" align="center" style="border:1px solid #cccccc;padding:1em;padding-top:0.5em;"| | ||
===Universities=== | ===Universities=== | ||
IMT Atlantique<br/> | |||
Université Grenoble Alpes, Grenoble INP<br/> | Université Grenoble Alpes, Grenoble INP<br/> | ||
Université Rennes 1, Rennes<br/> | Université Rennes 1, Rennes<br/> | ||
Latest revision as of 15:03, 11 June 2026
 Grid'5000 is a precursor infrastructure of SLICES-FR, the French node of SLICES-RI, Scientific Large Scale Infrastructure for Computing/Communication Experimental Studies.
|
|
Grid'5000 is a large-scale and flexible testbed for experiment-driven research in all areas of computer science, with a focus on parallel and distributed computing, including Cloud, HPC, Big Data and AI. Key features:
Older documents:
|
Random pick of publications
Five random publications that benefited from Grid'5000 (at least 2998 overall):
- Houssem Ouertatani. Efficient Deep Neural Architecture Search via Bayesian Optimization : An application to Computer Vision. Computer Vision and Pattern Recognition cs.CV. Université de Lille, 2024. English. NNT : 2024ULILB044. tel-05014154 view on HAL pdf
- Chih-Kai Huang. Scalability of public geo-distributed fog computing federations. Other cs.OH. Université de Rennes, 2024. English. NNT : 2024URENS055. tel-04910860v2 view on HAL pdf
- Guillaume Schreiner, Pierre Neyron. SLICES-FR : l’infrastructure de recherche nationale pour l’expérimentation Cloud et Réseaux du futur. JRES 2024 - Journées réseaux de l'enseignement et de la recherche, Renater, Dec 2024, Rennes, France. pp.1-15. hal-04893845 view on HAL pdf
- Mathis Guckert, Hélène Le Cadre, Jean Le Hénaff. A Generalized Potential Game Approach of UAV Swarm Coordination for Hidden Target Localization. IEEE Control Systems Letters, In press. hal-05252199v3 view on HAL pdf
- Donatien Schmitz, Guillaume Rosinosky, Etienne Rivière. Justin: Hybrid CPU/Memory Elastic Scaling for Distributed Stream Processing ⋆. DAIS 2025 - 25th International Conference on Distributed Applications and Interoperable Systems, Daniel Balouek; Ibéria Medeiros, Jun 2025, Lille, France. pp.1-17. hal-05081993 view on HAL pdf
Latest news
![]() Some clusters under Debian 13 "Trixie" environment by default and migration maintenance
Some clusters under Debian 13 "Trixie" environment by default and migration maintenance
Dear users,
The default standard environment has changed to Debian 13 for some
selected clusters over the past few weeks.
Here they are:
This is a key step towards the widespread deployment of Debian13. Most
clusters will be switched to a Debian 13 default environment Wednesday 26 August 2026.
If you need to, all the variants images (min, nfs, big) are available
for deployment, see `kaenv3 -l debian%13%` on frontends to list them.
Remember that there is a significant change concerning the modules. See
the preview announce : https://www.grid5000.fr/w/News#Upcoming_changes_to_modules
Best regards,
For Abaca and Grid'5000/SLICES-FR,
Nicolas Perrin
-- Grid'5000 Team 16:00, 02 Jul 2026 (CEST)
Hello everyone,
Let's start with a quick TLDR, details on the rationale and implementation are available below: new modules will be available with the new standard environment, and are already live for testing (but not activated by default).
If you want to test them you need to run the following commands:
unset MODULEPATH
module use /grid5000/guix-modules/x86_64/latest /grid5000/spack/module-others
Now for more details: for the past months we have been working on updating the standard environment and the way we provide modules.
The current way uses Spack under the hood, and is tightly bound to the underlying operating system.
It's been proven to be quite a burden for the team, and therefore we are changing the way we manage modules to:
- use a solution oblivious to the Linux flavor; - have means to update software versions automatically, and a clear release cycle; - actually have something reproducible; - be able to automatically test our most sensitive modules when they change (on both OAR and SLURM clusters).
Under the hood we switched to Guix to manage them²; it will be totally transparent for you.
The upcoming modules are located in `/grid5000/guix-modules/x86_64`, and you can try them today!
In order to use them you need to perform the following commands¹:
unset MODULEPATH
module use /grid5000/guix-modules/x86_64/latest
The list of modules for the `latest` release is available here:
https://api.grid5000.fr/explorer/software.
We know it's missing a few software compared to the current modules, we've tracked them here.
These should b...
![]() Changes to VS Code and AI Extensions Usage on Frontend
Changes to VS Code and AI Extensions Usage on Frontend
Recently, we have observed a critical increase in resource consumption (CPU and memory) on these nodes. This is primarily caused by VS Code Server (or similar) instances and associated AI-assisted coding extensions (such as Copilot, Tabnine, or local LLM agents) running directly on the frontend.
As a reminder, frontends are strictly dedicated to lightweight tasks: code editing, file management, and job submission. Running heavy background processes or AI agents on these shared machines degrades performance for the entire community and risks crashing the machines. Frontend are not sized for heavy code/system compilation/build either. Heavy tasks must be run on reserved nodes.
What is changing:
- ban on frontend: running VS Code Server (or similar), AI extensions, or any background development agents directly on the frontend will shortly be prohibited. - automated cleanup: we will actively monitor these nodes. Any unauthorized, resource-intensive processes or persistent VS Code servers found running on the login nodes will be terminated without prior warning.
How to continue using VS Code and AI tools?:
We fully understand that these tools could be essential for your work. Therefore, this usage is completely permitted and supported on the compute nodes.
To use VS Code and your AI agents properly, you must schedule an interactive session via the batch scheduler (OAR). You can do this by:
- Requesting an interactive allocation using oarsub -I.
- Tunneling your VS Code Remote-SSH connection directly to the allocated compute node instead of the frontend
This ensures you have dedicated resources for your AI tools without impacting other users.
-- Grid'5000 Team 16:00, 15 Jun 2026 (CEST)
![]() End of support for Rocky8/9 and ubuntu2004
End of support for Rocky8/9 and ubuntu2004
Support for the Rocky8/9 and Ubuntu2004 kadeploy environments is stopped due to the end of upstream support and compatibility issues with recent hardware.
The last version of the Rocky8 environments (version 2024071119), Rocky9 environments (version 2024071119), Ubuntu2004 environments (version 2025031116) will remain available on /grid5000.
Older versions can still be accessed in the archive directory (see /grid5000/README.unmaintained-envs for more information).
-- Grid'5000 Team 09:40, 10 May 2026 (CEST)
Grid'5000 sites
Current funding
INRIA
|
CNRS
|
UniversitiesIMT Atlantique |
Regional councilsAquitaine |

{kind=link}