Grid5000:Home
 Grid'5000 is a precursor infrastructure of SLICES-RI, Scientific Large Scale Infrastructure for Computing/Communication Experimental Studies.
|
|
Grid'5000 is a large-scale and flexible testbed for experiment-driven research in all areas of computer science, with a focus on parallel and distributed computing, including Cloud, HPC, Big Data and AI. Key features:
Older documents:
|
Random pick of publications
Five random publications that benefited from Grid'5000 (at least 2945 overall):
- Chih-Kai Huang, Guillaume Pierre. UnBound: Multi-Tenancy Management in Scalable Fog Meta-Federations. UCC 2024 - 17th IEEE/ACM International Conference on Utility and Cloud Computing, Dec 2024, Sharjah, United Arab Emirates. pp.1-11. hal-04760398 view on HAL pdf
- Antoine Franchini, Stéphane Girard, Anne Dutfoy. Adaptive confidence intervals for extreme quantiles from heavy-tailed distributions. 2025. hal-05322341v2 view on HAL pdf
- Théophile Dubuc. Détection d'anomalies de latence dans les systèmes distribués avec eBPF. Système d'exploitation cs.OS. Ecole normale supérieure de lyon - ENS LYON, 2024. Français. NNT : 2024ENSL0109. tel-05064342 view on HAL pdf
- Cherif Latreche, Nikos Parlavantzas, Hector A Duran-Limon. FoRLess: A Deep Reinforcement Learning-based approach for FaaS Placement in Fog. UCC 2024 - 17th IEEE/ACM International Conference on Utility and Cloud Computing, Dec 2024, Sharjah, United Arab Emirates. pp.1-9. hal-04791252 view on HAL pdf
- Gaspard Michel, Elena Epure, Romain Hennequin, Christophe Cerisara. Evaluating LLMs for Quotation Attribution in Literary Texts: A Case Study of LLaMa3. 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, Apr 2025, Albuquerque, New Mexico, United States. pp.742-755, 10.18653/v1/2025.naacl-short.62. hal-05245297 view on HAL pdf
Latest news
![]() Cluster Sasquatch is now in default queue at Grenoble
Cluster Sasquatch is now in default queue at Grenoble
We are pleased to announce that the Sasquatch [1] cluster is now available in the default queue.
Sasquatch is a cluster composed of 2 HPE RL300 nodes, each featuring:
This cluster was funded by the PEPR IA.
[1] https://www.grid5000.fr/w/Grenoble:Hardware#sasquatch
[2] https://amperecomputing.com/briefs/ampere-altra-family-product-brief
Best regards, Grid'5000 Technical Team
-- Grid'5000 Team 10:15, 11 February 2026 (CEST)
![]() Cluster Spirou is now in default queue at Louvain
Cluster Spirou is now in default queue at Louvain
We are pleased to announce that the Spirou[1] cluster of the newly installed Louvain site is now available in the default queue.
Spirou is a cluster composed of 8 Lenovo ThinkSystem SR630 V2 nodes, each featuring:
Be aware that we noticed I/Os inconsistencies on this cluster.
We advise users to take this into account when performing experimentations on the cluster. See the following bug for more information: https://intranet.grid5000.fr/bugzilla/show_bug.cgi?id=16938
This cluster was funded by the Fonds de la Recherche Scientifique – FNRS (F.R.S.–FNRS), and its operation is supported by F.R.S.–FNRS and the Wallonia region (SPW).
[1] https://www.grid5000.fr/w/Louvain:Hardware#spirou
Best regards,
Grid'5000 Technical Team
-- Grid'5000 Team 10:24, 12 January 2026 (CEST)
![]() End of support for centOS7/8 and centOSStream8 environments
End of support for centOS7/8 and centOSStream8 environments
Support for the centOS7/8 and centOSStream8 kadeploy environments is stopped due to the end of upstream support and compatibility issues with recent hardware.
The last version of the centOS7 environments (version 2024071117), centOS8 environments (version 2024071119), centOSStream8 environments (version 2024070316) will remain available on /grid5000. Older versions can still be accessed in the archive directory (see /grid5000/README.unmaintained-envs for more information).
-- Grid'5000 Team 08:44, 4 December 2025 (CEST)
![]() Ecotaxe cluster is now in default queue at Nantes
Ecotaxe cluster is now in default queue at Nantes
We are pleased to announce that the ecotaxe cluster of Nantes is now available in the default queue.
As a reminder, ecotaxe is a cluster composed of 2 HPE ProLiant DL385 Gen10 Plus v2 servers[1].
Each node features:
To submit a job on this cluster, the following command may be used:
oarsub -t exotic -p ecotaxe
This cluster is co-funded by Région Pays de la Loire, FEDER and REACT EU via the CPER SAMURAI [3].
[1] https://www.grid5000.fr/w/Nantes:Hardware#ecotaxe
[2] The observed throughput depends on multiple parameters such as the workload, the number of streams, ... [3] https://www.imt-atlantique.fr/fr/recherche-innovation/collaborer/projet/samurai
-- Grid'5000 Team 14:10, 02 December 2025 (CET)
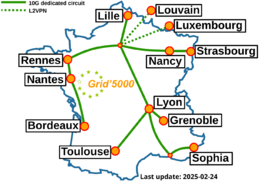
Grid'5000 sites
Current funding
INRIA
|
CNRS
|
UniversitiesIMT Atlantique |
Regional councilsAquitaine |

{kind=link}