Grid5000:Home
 Grid'5000 is a precursor infrastructure of SLICES-FR, the French node of SLICES-RI, Scientific Large Scale Infrastructure for Computing/Communication Experimental Studies.
|
|
Grid'5000 is a large-scale and flexible testbed for experiment-driven research in all areas of computer science, with a focus on parallel and distributed computing, including Cloud, HPC, Big Data and AI. Key features:
Older documents:
|
Random pick of publications
Five random publications that benefited from Grid'5000 (at least 2998 overall):
- Alix Tremodeux, Guillaume Pallez, Erven Rohou. How to determine a machine's true age in an HPC system?. JLESC 2026 -18th JLESC workshop, May 2026, Julich, Germany. hal-05662829 view on HAL pdf
- Guillaume Helbecque, Ezhilmathi Krishnasamy, Tiago Carneiro, Nouredine Melab, Pascal Bouvry. A Chapel-Based Multi-GPU Branch-and-Bound Algorithm. 22nd International Workshop on Algorithms, Models and Tools for Parallel Computing on Heterogeneous Platforms, Aug 2024, Madrid, Spain. pp.463-474, 10.1007/978-3-031-90200-0_37. hal-04709106 view on HAL pdf
- Rahma Hellali, Zaineb Chelly Dagdia, Karine Zeitouni. A Multi-Objective Multi-Agent Interactive Deep Reinforcement Learning Approach for Feature Selection. International conference on neural information processing, Dec 2024, Auckland (Nouvelle Zelande), New Zealand. pp.15. hal-04723314 view on HAL pdf
- Georges da Costa. Hardware and application aware performance, power and energy models for modern HPC servers with DVFS. Sustainable Computing : Informatics and Systems, 2025, 46, pp.101106. 10.1016/j.suscom.2025.101106. hal-04983485 view on HAL pdf
- Romaric Pegdwende Nikiema, Marcello Traiola, Angeliki Kritikakou. Impact of Compiler Optimizations on the Reliability of a RISC-V-based Core. DFT 2024 - 37th IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems, Oct 2024, Oxfordshire, United Kingdom. pp.1-1. hal-04731794 view on HAL pdf
Latest news
![]() Some clusters under Debian 13 "Trixie" environment by default and migration maintenance
Some clusters under Debian 13 "Trixie" environment by default and migration maintenance
Dear users,
The default standard environment has changed to Debian 13 for some
selected clusters over the past few weeks.
Here they are:
This is a key step towards the widespread deployment of Debian13. Most
clusters will be switched to a Debian 13 default environment Wednesday 26 August 2026.
If you need to, all the variants images (min, nfs, big) are available
for deployment, see `kaenv3 -l debian%13%` on frontends to list them.
Remember that there is a significant change concerning the modules. See
the preview announce : https://www.grid5000.fr/w/News#Upcoming_changes_to_modules
Best regards,
For Abaca and Grid'5000/SLICES-FR,
Nicolas Perrin
-- Grid'5000 Team 16:00, 02 Jul 2026 (CEST)
Hello everyone,
Let's start with a quick TLDR, details on the rationale and implementation are available below: new modules will be available with the new standard environment, and are already live for testing (but not activated by default).
If you want to test them you need to run the following commands:
unset MODULEPATH
module use /grid5000/guix-modules/x86_64/latest /grid5000/spack/module-others
Now for more details: for the past months we have been working on updating the standard environment and the way we provide modules.
The current way uses Spack under the hood, and is tightly bound to the underlying operating system.
It's been proven to be quite a burden for the team, and therefore we are changing the way we manage modules to:
- use a solution oblivious to the Linux flavor; - have means to update software versions automatically, and a clear release cycle; - actually have something reproducible; - be able to automatically test our most sensitive modules when they change (on both OAR and SLURM clusters).
Under the hood we switched to Guix to manage them²; it will be totally transparent for you.
The upcoming modules are located in `/grid5000/guix-modules/x86_64`, and you can try them today!
In order to use them you need to perform the following commands¹:
unset MODULEPATH
module use /grid5000/guix-modules/x86_64/latest
The list of modules for the `latest` release is available here:
https://api.grid5000.fr/explorer/software.
We know it's missing a few software compared to the current modules, we've tracked them here.
These should b...
![]() Changes to VS Code and AI Extensions Usage on Frontend
Changes to VS Code and AI Extensions Usage on Frontend
Recently, we have observed a critical increase in resource consumption (CPU and memory) on these nodes. This is primarily caused by VS Code Server (or similar) instances and associated AI-assisted coding extensions (such as Copilot, Tabnine, or local LLM agents) running directly on the frontend.
As a reminder, frontends are strictly dedicated to lightweight tasks: code editing, file management, and job submission. Running heavy background processes or AI agents on these shared machines degrades performance for the entire community and risks crashing the machines. Frontend are not sized for heavy code/system compilation/build either. Heavy tasks must be run on reserved nodes.
What is changing:
- ban on frontend: running VS Code Server (or similar), AI extensions, or any background development agents directly on the frontend will shortly be prohibited. - automated cleanup: we will actively monitor these nodes. Any unauthorized, resource-intensive processes or persistent VS Code servers found running on the login nodes will be terminated without prior warning.
How to continue using VS Code and AI tools?:
We fully understand that these tools could be essential for your work. Therefore, this usage is completely permitted and supported on the compute nodes.
To use VS Code and your AI agents properly, you must schedule an interactive session via the batch scheduler (OAR). You can do this by:
- Requesting an interactive allocation using oarsub -I.
- Tunneling your VS Code Remote-SSH connection directly to the allocated compute node instead of the frontend
This ensures you have dedicated resources for your AI tools without impacting other users.
-- Grid'5000 Team 16:00, 15 Jun 2026 (CEST)
![]() End of support for Rocky8/9 and ubuntu2004
End of support for Rocky8/9 and ubuntu2004
Support for the Rocky8/9 and Ubuntu2004 kadeploy environments is stopped due to the end of upstream support and compatibility issues with recent hardware.
The last version of the Rocky8 environments (version 2024071119), Rocky9 environments (version 2024071119), Ubuntu2004 environments (version 2025031116) will remain available on /grid5000.
Older versions can still be accessed in the archive directory (see /grid5000/README.unmaintained-envs for more information).
-- Grid'5000 Team 09:40, 10 May 2026 (CEST)
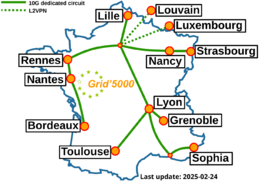
Grid'5000 sites
Current funding
INRIA
|
CNRS
|
UniversitiesIMT Atlantique |
Regional councilsAquitaine |

{kind=link}